
Table of Contents
- Prerequisites
- Validate Consul server disk configurations
- Determining Current VM Disk I/O Throughput
- Using iostat to find Disk I/O issues
- Using pidstat to correlate i/o wait with Consul
- Using raft replication metrics to infer Disk I/O issues
- Useful Links
Prerequisites
The troubleshooting below relies on a few different CLI utilities. They are typically already installed on linux systems and you shouldn't need to install them. However, if you find that they aren't on the customer's machine, here's a list of the packages that are required:
- sysstat (
iostatandpidstat) - util-linux (
lsblk)
Validate Consul server disk configurations
As a basic first step, it's good to validate the Consul server's disk configuration. In some situations, customers might have inadvertently provisioned disks differently across their server nodes (e.g., they may have provisioned 3 initially, then added two later with different disk types).
Determine the disk or partition of Consul's data directory
Before looking into the disk configuration, it can be useful to determine exactly which disk Consul's data directory is being stored on. To discover this, find the path to the data directory and then run this command:
df -h /path/to/data/directory
It will print out which disk or partition the directory is stored on and might look something like this:
$ df -h /storage1/consul/data
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p2 916G 75G 795G 9% /
Based on that output, you can see that the data directory is on the /dev/nvme0n1 disk.
Check disk sizes and layout
For a basic sanity check, we need to make sure all server nodes have the same partition/disk layout and disk sizes.
To perform a spot check you can run the following command:
df -h
This will print out a list of all disks and mounts on the system, including their size and utilization. The output across all server nodes should look very similar with only minor variations in Use%. All disk/partition sizes should be the same. Any discrepancies could be cause for concern.
You can get more information by running this:
sudo lsblk -o NAME,FSTYPE,LABEL,MOUNTPOINT,SIZE,MODEL
which would produce output along these lines:
sda 931.5G Samsung SSD 860
└─sda1 ext4 931.5G
sdb 931.5G Samsung SSD 860
└─sdb1 ext4 931.5G
sdc 931.5G Samsung SSD 860
└─sdc1 ext4 931.5G
nvme0n1 931.5G Samsung SSD 970 EVO Plus 1TB
├─nvme0n1p1 1M
└─nvme0n1p2 ext4 / 931.5G
Once again, the output should be more or less identical when it comes to disk types and sizes. Utilization might vary slightly between nodes, but should be in the same ballpark.
Questions to Ask
If you see discrepancies (e.g., disk layout or sizes differ, disk types differ, etc.), here are some things to focus on:
- Compare disk type being used across nodes (e.g., if they're Azure VMs, get them to pull up the disk information and get Azure disk types).
- Are they all SSDs?
- What are the differences in IOPS between disks?
- Does one disk type have an IOP cap that differs from another?
Remediation
Assuming you've discovered that the nodes have varying disk types and some are underperforming here are the basic steps to remediate:
- Add a new SSD disk with appropriate IOP throughput to all Consul server VMs.
- Mount the disk at a new location on the VM.
- Stop the Consul service.
- Copy the Consul data directory to the new mount drive.
- Update the Consul config's
data_dirto point to the new location. - Start the Consul service.
Repeat that process for each of the followers and then the leader.
Determining Current VM Disk I/O Throughput
| Cluster Size |
Disk Throughput (MB/s) |
| Small | 75 + MB/s |
| Large | 250+ MB/s |
When trying to determine if the OS's Hardware disks are provisioned to support Reference Architecture Disk Throughput, a simple file transfer test can be ran utilizing the Linux ddcommand. dd is a command line tool utilized primarily to convert and copy files. In this example a 1GB test file named test1.imgis transferred from the /dev/zero input source to the current directory.
dd command line:
time dd if=/dev/zero of=./test1.img bs=1G count=1 oflag=dsync
Allow time for this command to complete and you'll receive an output similar to the one shown below where you'll be able to determine the MB/s Disk Throughput capabilities currently available to the VM.
[root@host]#
1+0 records bin
1+0 records output1073741824 bytes (1.1 GB) copied, 181.758 s, 5.9 MB/s <--- MB/s = Disk Throughput
real 3m1.766s
user 0m0.001s
sys 0m1.083sUsing iostat to find Disk I/O issues
Typically, disk i/o problems surface in the form of elevated disk i/o wait time. The easiest way to see this is by using iostat. Typical usage looks something like this:
sudo iostat -x -m 1
If the machine has a lot of disks and you're only interested in a couple, you can add them as parameters at the end to limit output to just those disks:
sudo iostat -x -m 1 sda sdb sdc
That will produce output similar to this:
avg-cpu: %user %nice %system %iowait %steal %idle
0.01 0.00 0.01 0.02 0.00 99.96
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
What you're looking for is a high value in the %iowait summary at the top or high values of %util in the farthest right column. Here's an example of a system with a high amount of iowait:
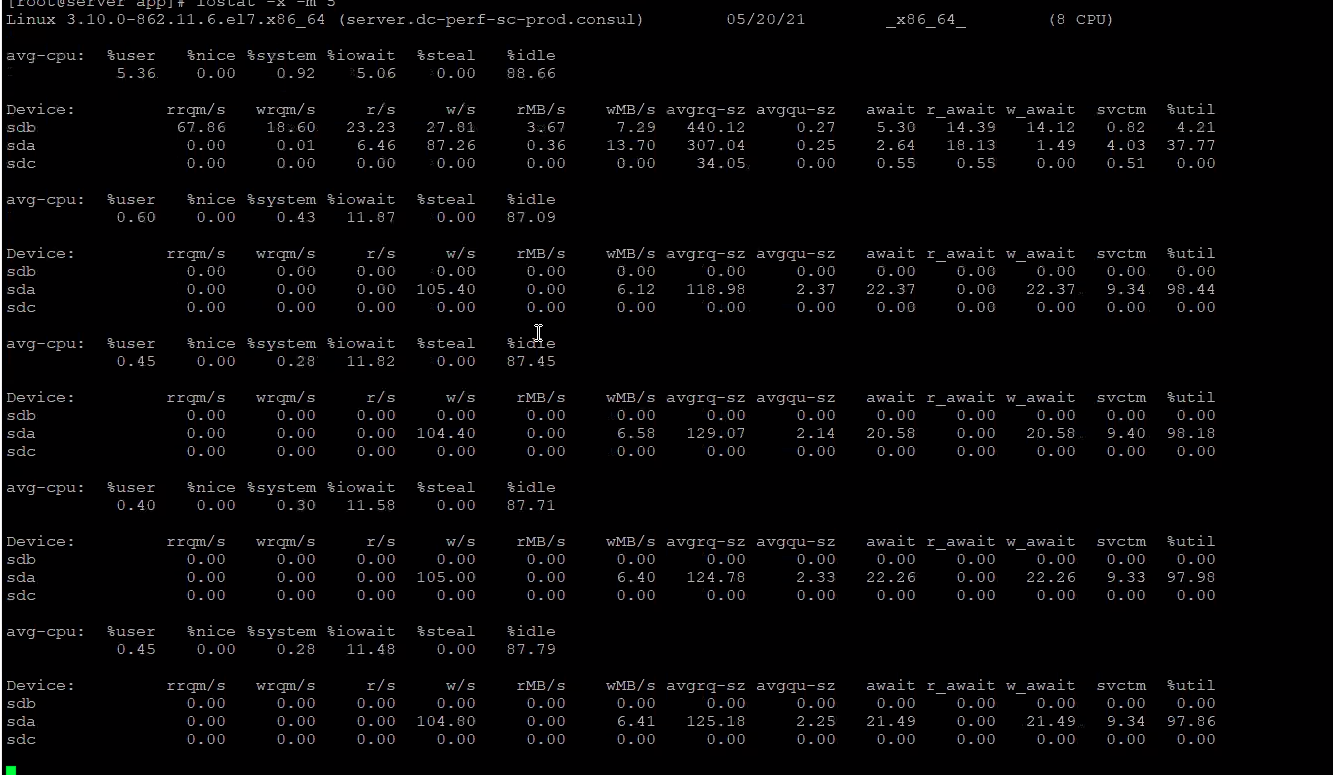
Notice how the %util for sda is consistently in the high 90s. This is a clear indicator that the disk is maxed out and will likely be experiencing i/o wait. You can also see that %iowait is around 11-12%, which is quite high. Typically, that is less than 2% and more often less than 1%.
Questions to Ask
Assuming you've found some i/o wait:
- Are all Consul servers exhibiting i/o wait? Or are just some?
- If only some, take another look at the disks to ensure the underperforming disks aren't a different type with lower performance capabilities.
- If all disks are exhibiting i/o wait, then they should consider upgrading to higher throughput/IOPS disks.
- Do they have historical disk metrics for these machines that would let you track disk i/o over time?
- If so, check to see if this issue has always existed or just started. If it always existed, then they may have just under-provisioned their disks. If it just started, then there is likely a precipitating incident (e.g., increased Vault usage, server maintenance that impacted storage, etc.).
Using pidstat to correlate i/o wait with Consul
If you've established that the node Consul server is running on has i/o wait – the odds are good that it's being caused by Consul's usage and typically this is related to underlying disk throughput. However, it can be handy to be able to ensure the i/o wait you're seeing is being caused by Consul and not some other process. To do that, you can use the pidstat command. This will display CPU utilization and i/o wait by process:
sudo pidstat -d 1
That will print out a reading every 2 seconds until canceled. When canceled it prints out a summary of average usage over the timeframe that was examined. Output might look something like this:
Linux 4.15.0-142-generic (moria) 05/20/2021 _x86_64_ (32 CPU)
07:40:26 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
07:40:28 PM 0 740 0.00 93.07 0.00 0 systemd-journal
07:40:28 PM 102 2048 0.00 5.94 0.00 0 rsyslogd
07:40:28 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
07:40:30 PM 0 740 0.00 30.00 0.00 0 systemd-journal
07:40:30 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
07:40:32 PM 0 662 0.00 18.00 0.00 1 jbd2/nvme0n1p2-
07:40:32 PM 0 740 0.00 36.00 0.00 1 systemd-journal
07:40:32 PM 102 2048 0.00 2.00 0.00 0 rsyslogd
^C
Average: UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
Average: 0 662 0.00 5.98 0.00 0 jbd2/nvme0n1p2-
Average: 0 740 0.00 53.16 0.00 0 systemd-journal
Average: 102 2048 0.00 2.66 0.00 0 rsyslogd
Using raft replication metrics to infer Disk I/O issues
Although it's typically easier to find disk i/o issues using iostat, if you only have access to telemetry metrics, you can infer disk i/o issues from certain metrics.
Enabling the metrics endpoint and capturing metrics
This metrics information is available inside consul debug output, but it uses a metrics endpoint that isn't very reliable. To get the best information you need to use the Prometheus metrics endpoint. Unfortunately, this endpoint isn't enabled by default and the config entry that enables it isn't hot reloadable. To enable it, you need to add the following entry to the Consul server configs:
telemetry {
prometheus_retention_time = "10s"
}
Once you've enabled the endpoint, you can fetch metrics via curl like this:
curl -s -H "X-Consul-Token: $TOKEN" http://127.0.0.1:8500/v1/agent/metrics?format=prometheus
That will print out all the metrics that are available. Generally speaking, you'll want the customer to run this several times in a loop to fetch metrics samples over a period of time. Something like this will do:
export CONSUL_HTTP_TOKEN=your-token-here
export CONSUL_HTTP_ADDR=http://127.0.0.1:8500
for i in $(seq -w 30); do
curl -s -H "X-Consul-Token: $CONSUL_HTTP_TOKEN" $CONSUL_HTTP_ADDR/v1/agent/metrics?format=prometheus > consul-metrics-dump_$HOSTNAME_$i.txt
sleep 2
done
That will capture 30 samples over 60 seconds and store each sample in a separate file. The customer should run this on each server, zip the files up and send them to us for examination.
Which metrics to pay attention to
The transaction timing metrics can be used to determine if the node you're looking at metrics for is experiencing disk slowness or other issues.
Performance for a cluster can suffer too even when the transaction timing metrics look good for on the leader node. The reason for this stems from raft replication timing. For writes to be considered "committed" they have to be written to a quorum of servers. This means that if some of the other servers are having disk i/o or performance problems, then the whole cluster will suffer. One way to detect this is by looking at the consul.raft.replication.appendEntries.rpc metric. As per the docs:
Measures the time taken (in ms) by the append entries RFC, to replicate the log entries of a leader agent onto its follower agent(s)
Here's an example in an environment where the underlying deployment had several servers with slower disks that ended up having IOPS limits lower than other servers in the cluster:
grep appendEntries consul-metrics-dump_$HOSTNAME_*.txt | grep 0.99
consul_raft_replication_appendEntries_rpc_1858fb51_6eba_514c_7c2a_9319178f7b0d{quantile="0.99"} 18.828672409057617
consul_raft_replication_appendEntries_rpc_a1787e90_a496_5094_56ce_846b64a14f56{quantile="0.99"} 12103.166015625
consul_raft_replication_appendEntries_rpc_dc25371a_264f_963b_be09_536c60435a6f{quantile="0.99"} 7684.35205078125
consul_raft_replication_appendEntries_rpc_ee897d6d_d430_2f70_985d_c51aea081c51{quantile="0.99"} 141.42955017089844
The UUID at the end of the metric names correlates to the Consul server node ID, which you can see in consul operator raft list-peers output. Here's the output from the cluster the above came from:
# consul operator raft list-peers
Node ID Address State Voter RaftProtocol
perf-sc-prod-consul_4 1858fb51-6eba-514c-7c2a-9319178f7b0d 10.74.140.13:8300 follower true 3
perf-sc-prod-consul_0 a1787e90-a496-5094-56ce-846b64a14f56 10.74.140.9:8300 follower true 3
perf-sc-prod-consul_1 ee897d6d-d430-2f70-985d-c51aea081c51 10.74.140.10:8300 follower true 3
perf-sc-prod-consul_3 dc25371a-264f-963b-be09-536c60435a6f 10.74.140.12:8300 follower true 3
perf-sc-prod-consul_2 05825693-7016-5b0d-56aa-4905ce3a9f11 10.74.140.11:8300 leader true 3
As you can see from the metrics, consul_4 had very fast disk. consul_1 was quite a bit slower, but still fast relatively speaking. consul_0 and consul_3 were very slow. Note that we don't have metrics for consul_2 because it's the leader and this metric is measuring the time it takes to replicate to followers.
This information is enough to let you know there does appear to be a problem on followers that needs further investigation. In the above case, 3 of the 5 servers were on SSD disks, but the allowed IOPS was more limited than the other 2 servers.